Artikel
Auf dieser Seite finden sich die aufbereiteten heute noch relevanten Artikel aus meinem ehemaligen Blog vom ASP.NET Zone Forum.
Design Patterns
- Teil 1: Umkehrung der Kontrolle erklärt, oder: Von der Fabrikmethode zum DI-Container
- Teil 2: Umkehrung der Kontrolle erkärt, oder: Von der Fabrikmethode zum DI-Container
.NET Allgemein
- Richtig testen, oder: Was ist schneller… Foreach, LAMBDA Expressions, oder LINQ?
- Fehler verstecken leicht gemacht
- Wann IEnumerable nutzen, wann ICollection und wieso überhaupt IList?
ASP.NET Grundlage
- ASP.NET Grundlagen Teil 1: Ein Blick hinter die Kulisse
- ASP.NET Grundlagen Teil 2: Tschüss Statuslosigkeit
C#
Teil 1: Umkehrung der Kontrolle erklärt, oder: Von der Fabrikmethode zum DI-Container
Dies ist der Beginn der Artikelserie "Umkehrung der Kontrolle erkärt, oder: Von der Fabrikmethode zum DI-Container" mit folgenden Teilen:
- Teil 1 (Dieser Artikel)
- Teil 2 Umkehrung der Kontrolle erkärt, oder: Von der Fabrikmethode zum DI-Container
LightCore (Siehe: LightCore auf github.com) gibt es schon seit längerer Zeit, andere DI-Container noch länger.
In dieser Blogpostreihe geht es aber nicht primär um LightCore, auch nicht um die anderen DI-Container.
Ich möchte mit diesem Blogpost versuchen zu erkären, wie denn die ganze Geschichte funktioniert.
Vom Ursprung bis zu einer implementierten Komponente.
Das Feedback zur LightCore-Webseite und LightCore selber hat auf alle Richtungen ausgeschlagen.
Von: Wow, cool. Brauche ich!, zu: Was ist das denn?, bis zu: Braucht man sowas?, über: Sowas braucht man nicht!, bis zu: Mache ich von Hand oder in 10 Zeilen!.
An dieser Stelle sei gesagt: Ich würde die Fragen nach dem "brauchen" in jedem Fall mit "Ja" beantworten, je nach Kontext wo denn etwas eingesetzt werden soll.
Die Grundprobleme:
- Abhängigkeit zu konkreten Typen
- Redundanz bei der Konstruktion von Typen jeglicher Art
- Keine einfache Möglichkeit der Austauschbarkeit von Typen
- Keine einfache Möglichkeit der Erweiterbarkeit über Typen
Wieso überhaupt "Abhängigkeit lösen"?
Um die Probleme 2, 3 bis 4 zu lösen. Das heisst, die möglichen Redundanzen - also bspw. doppelten Instanziierungen von Klassen - zu vermeiden. Durch das Lösen der Abhänigigkeit von einem konkreten zu einem abstrakten Typen können die Typen ausgetauscht werden und eine Erweiterung ist mit weniger Aufwand möglich.
Die Abhängigkeit wird nicht "verbannt", sondern gelöst. Lösen heisst in diesem Fall, dass die Abhängigkeit nicht mehr auf _einen_ _konkreten_ Typen besteht, sondern auf _eine_ Abstraktion, die _mehrere_ unterschiedliche Implementationen beinhalten kann.
Anstelle dass nur "World" genutzt werden kann, kann dann mithilfe der Abstraktion "WorldBase", "SecondWorld", "IrgendwasWorld", etc... benutzt werden.
Diese Grundprobleme können auf verschiedene Arten gelöst werden. Vorerst die einfachsten Möglichkeiten.
Eine einfache Abhängigkeit zu konkreten Typen kann folgendermassen aussehen:
In diesem Beispiel ist die Methode "SayHello" von der konkreten Klasse "World" abhängig.
Wollen wir diese Abhängigkeit lockern / lösen, brauchen wir eine Abstraktion irgend einer Art.
Das kann ein Interface sein, eine Abstrakte Klasse oder auch eine einfache konkrete Oberklasse.
Am Beispiel einer abstrakten Klasse:
Ja, das war erst der erste Schritt. Das Problem besteht immer noch, es liegt in "new World();". Wir referenzieren den Konstruktur der konkreten Klasse.
Die einfachste Lösung hierfür ist eine Fabrikmethode (Factory Method), womit die Konstruktion der Instanz ausgelagert wird.
Dies könnte so aussehen:
So ist das Problem auf einfachste Art gelöst.
Zusammenfassung:
Das Problem war die Abhängigkeit auf die konkrete Klasse "World".
Wenn wir anstelle von der Klasse "World", "SecondWorld" benutzen wollen, brauchen wir das jetzt nur noch an der Stelle "return new World" zu ändern, in "return new SecondWorld();"
Wie häufig wir die Fabrikmethode "ConstructMyWorld" benutzen, bleibt uns überlassen.
Die Stelle bleibt, ein Ort der Änderung.
Das wird möglich indem wir eine Abstraktion benutzen, in unserem Falle "WorldBase".
Die konkreten Klassen "World", "SecondWorld" müssen von aussen gleich aussehen (Implementieren die gleiche Abstraktion), können allerdings anders implementiert sein.
Die Angabe des Typs "WorldBase" braucht bei der Zuweisung am Ort des Benutzens angegeben werden, sowie auch als Rückgabetyp der Fabrikmethode.
Das war die einfachste Möglichkeit der Umkehrung per Fabrikmethode.
Die Frage bleibt evt. noch: Wieso Umkehrung?
Am Anfang hatte die Zuweisung am Ort des Benutzens die Kontrolle über den konkreten Typen, sie gab also an, was sie möchte.
Jetzt liegt die Kontrolle _in_ der Fabrikmethode. Der Ort des Benutzens weiss nur, das da ein Typ zurückkommt, der aussieht wie "WorldBase", nicht mehr und nicht weniger.
Am Schluss noch der vollständige (vermutlich nicht sofort lauffähige = Pseudo) Code:
Teil 2: Umkehrung der Kontrolle erklärt, oder: Von der Fabrikmethode zum DI-Container
Dies ist die Fortsetzung der Artikelserie "Umkehrung der Kontrolle erkärt, oder: Von der Fabrikmethode zum DI-Container" mit folgenden Teilen:
- Teil 1: Umkehrung der Kontrolle erkärt, oder: Von der Fabrikmethode zum DI-Container
- Teil 2 (Dieser Artikel)
Der erste Teil liegt schon eine Zeit zurück, das hindert mich aber nicht daran, da doch noch mehr zu veröffentlichen.
Ein Rückblick auf Teil 1:
Wir haben Abhängigkeiten angeschaut, worin die Probleme liegen wie sie mithilfe der Umkehrung der Kontrolle mittels Factory Methode umgangen werden können.
Es gibt noch das Abstract Factory Pattern, von der Gang of Four folgendermassen beschrieben:
- Eine Schnittstelle Abstract Factory, die nur die Interfaces der Produkte zurückgibt.
- N konkrete Implementationen wie z.B. Concrete Factory A.
- Implementationen von den Produkten
Dieses Pattern erinnert mich an das Provider Pattern, wo es einen abstrakten Provider und bspw. FileProvider und SqlProvider gibt.
Einfach das in diesem Fall hier Objekte in verschiedenen Familien erzeugt werden, anstelle ein Verhalten in verschiedenen Familien zu repräsentieren.
Ich habe es in dieser Form noch nie genutzt aber es gibt sicher Einsatzfälle und Abwandlungen davon.
Das war jetzt ein kleiner Ausflug in die Patterns, aber eigentlich ging es darum, den Weg von der Fabrikmethode zum DI-Container zu beschreiben.
Eine Fabrikmethode ist das Mittel des DI-Containers, der dafür gedacht ist das schreiben und verwalten von vielen Factorymethoden zu ersparen. Er stellt eine globale Factorymethode dar, die über den Interfacetyp eine konkrete Klasse zurückgibt, die im Container registriert ist.
Er geht noch weiter indem er ganze Objekthierarchien von Abhängigkeiten in Form von Konstruktorargumenten oder Eigenschaften auflösen kann.
Diese gewonnene Bequemlichkeit forciert auch das Unterteilen von Code in mehrere Klassen, die jeweils dedizierte Aufgaben haben und dann per Container injiziert werden können.
Ich habe länger überlegt, was ich noch in diesen Artikel bringen soll. Es gibt sehr viele simple, einfache Beispiele für einen Container.
Zum Abschluss gibt es noch den Quellcode des Vorgängers von LightCore, der schon einiges konnte aber viel viel kleiner war als die aktuelle Version von LightCore.
Richtig testen, oder: Was ist schneller… Foreach, LAMBDA Expressions, oder LINQ?
Einleitung
Der schweizer Kollege Daniel Schädler hat einen Blogpost mit dem Titel “Was ist schneller… Foreach, LAMBDA Expressions, oder LINQ?” veröffentlicht.
Daniel hat sich die Frage gestellt, was wohl schneller ist: Listen per foreach, über LINQ oder die Erweiterungsmethoden Syntax für LINQ filtern.
Nun, ich wusste natürlich schon vorher, dass die Resultate nur ganz wenig auseinander liegen dürfen, weil:
- Wird die LINQ-Syntax in den Erweiterungsmethoden-Syntax übersetzt (Nahezu gleich).
- Arbeitet LINQ intern auch mit den Iteratoren, wie sie in foreach genutzt werden. Siehe Enumerable-Klasse im Reflector.
Abgesehen davon nutze ich diese Antwort in Form eines Blogposts einfach mal dazu, wie ich Geschwindigkeiten teste, auch wenn es in diesem Fall für mich theoretisch klar war, das alle in etwa gleich schnell sind.
Es braucht für einen Geschwindigkeitstest nicht unbedingt eine grafische Anwendung, auch wenn das natürlich nicht schlecht ist. Ich habe mir den Aufwand nicht gemacht und mich auf das Wesentliche konzentriert: Das Testen.
Verfälschte Tests und wie sie verhindert werden können
Der Test von Daniel liefert leider das falsche Resultat, sogar ein sehr verfälschtes.
Das liegt daran, das die Ergebnisse von LINQ bzw. den Erweiterungsmethoden als IEnumerable<T> zurückgegeben werden und diese zeitverzögert ausgeführt werden (deferred Execution).
Das heisst der ganze Code der die IEnumerable<T> Instanz liefert, wird erst ausgeführt, wenn das Ergebnis tatsächlich durchlaufen wird.
Dies kann bspw. mit <Menge>.Count(), <Menge>.ToList(), … angestossen werden.
Erst dann, und wirklich erst dann wird der Code überhaupt ausgeführt und braucht dann eben auch länger.
Auch wenn dies geschehen ist, bleibt das Ergebnis von Daniel noch verfälscht, denn eine Testiteration kann durch mehrere Faktoren verfälscht werden.
Sei das eine einmalige Kompilation einer Abfrage zur Laufzeit oder durch diversen Hintergrundprozessen die genau in dem Moment mehr Leistung benötigen als beim vorherigen Testkandidaten.
Es heisst also: Mehrere Iterationen einer Operation die getestet werden will, ausführen.
Darüber hinaus ist es noch so, dass das Gesamtergebnis auch noch bei mehreren Iterationen der zu testenden Operation verfälscht sein kann, weil eben die erste ausgeführte Operation verfälscht ist.
Um da einen Mittelwert zu bekommen, macht man über die ganzen Testläufe nochmals mehrere Testläufe.
Das hört sich jetzt womöglich ein bisschen verwirrend an, jedoch meine ich einfach gesagt nur folgendes:
- Eine Operation: Einträge aus einer Menge filtern
- Mehrere Iterationen einer Operation: Die Operationen mehrmals ausführen
- Das ganze für alle Testkandidaten mehrmals ausführen
Somit kann man sehr sicher sein, dass die Ergebnisse der verschiedenen Kandidaten realistisch miteinander vergleichbar sind, nicht aber dass die Werte 1:1 dem entsprechen, wie sie dann auch in der Produktivumgebung auftreten, denn dort kommen wieder andere Faktoren dazu.
Nur das keine Missverständisse auftreten: Natürlich ist dann ein solcher Test auch für die Praxis aussagekräftig, nur wird er nicht 100% gleich ausfallen, wenn man die Zeit stoppt.
Als Testhilfe würde ich nicht DateTime.Now, etc.. benutzen, da dies zu ungenau ist. Das meines Wissens genauste Instrument das ohne P/Invoke-Aufrufe in unmanaged Code verfügbar ist, heisst Stopwatch und ist im System.Diagnostics-Namespace zu finden.
Mittels der Eigenschaft <Stopwatch>.ElapsedMilliseconds lassen sich die Millisekunden auslesen, die seit dem Start- und Stopaufruf vergangen sind, das reicht uns für den Test und ist auch aussagekräftig und vorstellbar, was bei den von Daniel genutzten Ticks m.E. nicht der Fall ist.
Für die Tests nutze ich eine Methode namens SpeedTest die einen Action-Delegate entgegennimmt den sie n-Mal ausführt.
So kann das Testen zentralisiert werden und ist mit sehr kleinem Aufwand möglich den Test selber zu erweitern, sowie neue Kandidaten hinzuzufügen.
Wenn der Test ausgeführt wird, habe ich Abweichungen von 1 bis 4 Millisekunden und das bei sehr vielen Durchläufen. Diese Abweichungen sind für mich also – wie am Anfang vermutet – irrelevant.
Folgend den Code der ich für meinen Test verwendet habe:
Fehler verstecken leicht gemacht
Mit Try / Catch / Finally können in .NET Fehler behandelt werden.
Eigentlich eine gute Sache, allerdings sollte man aufpassen wo und wie man Fehler behandelt.
Vielerorts kann gelesen werden, dass das Fangen einer Allgemeinen Exception nicht gut sei, aber wieso ist das so?
Da ich es auch schon selber praktisch mehrmals erlebt habe, was das für schlimme Auswirkungen haben kann, ist es für mich nicht so schwer, diese Frage zu beantworten.
Ich möchte dies anhand eines kleinen, nachvollziehbaren Beispiels erläutern.
Gegeben ist folgender Code:
Dieser Code, läuft - wie er jetzt da steht - ohne Probleme, solange die Daten nie als readonly gekennzeichnet werden.
Wird jetzt allerdings der Code erweitert, gibt es ein höchst merkwürdiges Verhalten, das ich mir zuerst überhaupt nicht erkären konnte.
Folgende Änderung:
wird zu:
Der erste Teil der Bedingung liefert mit der Negation schlussendlich true und die Sicherheitsabfrage false, was ausgewertet dann einem false entspricht.
Somit werden die Löschen-Buttons nicht dargestellt. Gut. Eigentlich genau das was ich wollte.
Jedoch – und jetzt kommt der Haken – wird jetzt nur noch ein Datensatz im GridView angezeigt, anstelle von den zwei die in der Datenquelle vorhanden sind.
Im ersten Moment kam mir das ziemlich merkwürdig vor, da ich auch nirgendwo nochmals auf die Bedingung zugreifen und vor allem, weil auch kein Fehler geworfen wurde.
Kurz nachdem ich den Debugger angeworfen und kurz in den EventHandler “GridView1_RowDataBound” reingeschaut habe, kam es mir in den Sinn:
Böses Try / Catch, ein Fehler wurde versteckt, ohne das ich es gemerkt habe.
Was ist denn genau passiert?
Nun, da über die komplette Page_Load-Methode ein Try / Catch Konstrukt gespannt ist, das generell alle Fehler abfängt (Nicht behandelt, sondern eben “verschluckt”), bekomme ich den Fehler nicht zu Gesicht und der Code läuft in einem inkonsistenten Zustand weiter.
Der Eventhandler wird angemeldet und ein GridView1.DataBind()-Aufruf läuft im Eventhandler selber, also auch im Scope von besagtem Try / Catch, sodass die NullReferenceException, die eigentlich geworfen werden sollte, verschluckt wird.
Das hat dann dazu geführt, dass das GridView “irgendwie” noch halb fertig gerendert wird und man nichts vom Fehler mitbekommt, sondern eben nur einen Datensatz halb fertig gerendert wird.
Ich hoffe das dieses Beispiel ein wenig Klarheit bringt und vor allem euch aufweckt, Exception Handling mit Bedacht einzusetzen und nicht an einem solch komischen Verhalten zu verzweifeln.
Zusatz / Fazit:
Wie man sehen kann, ist der Scope (Wirkungsbereich) von Try / Catch um die ganze Page_Load-Methode gelegt.
Dies kann Sinn machen, jedoch nicht in der Mehrzahl der Fälle, wie auch in diesem Fall.
Meiner Meinung nach, und so steht es auch in den meisten Büchern, sollten Fehler punktuell abgefangen werden, nur dort wo man ihn auch behandeln kann und der Scope sollte möglichst klein gehalten werden, damit das Problem auch schnell identifiziert ist.
Die unbehandelten Fehler kann man dann generell in ASP.NET bspw. in der Global.asax.cs in der Methode Application_Error() loggen.
Ich persönlich gehe sogar so vor, das ich zuerst ohne Fehlerbehandlung entwickle und diese erst später hinzufüge.
So gehen während der Entwicklung keine Fehler vergessen und das Programm befindet sich nie in einem inkonsistenten Zustand.
Wann IEnumerable nutzen, wann ICollection und wieso überhaupt IList?
Es gibt einige Mengen- / Auflistungstypen in .NET.
Ein kleine Auswahl:
Früher gab es nur nicht generische bzw. keine stark typisierte Collections, die heute nicht mehr verwendet werden sollten,
da immer explizit gecastet werden muss, was umständlich ist und Performance kostet.
Hierfür zitiere ich gerne herbivore aus myCSharp:
ArrayList gehört in die Mottenkiste und sollte wie alle untypisierten Collections aus System.Collections nicht mehr benutzt werden. Verwende stattdessen List<T> und alle anderen typisierten Collections aus System.Collections.Generic.
Ich möchte hier allerdings nicht die verschiedenen Auflistungstypen im Detail anschauen, sondern herausfinden, wann welcher konkreter Typ oder gar das Interface in einer Signatur verwendet werden sollte.
Ein kleines Beispiel:
Dieser Code verwendet List<T> als Argumenttyp, es besteht also eine Abhängigkeit darauf,
d.h. jeder Aufrufer muss hier eine List<T> übergeben, alles andere funktioniert nicht.
Beispielsweise kann hier kein Array übergeben werden, oder eine Collection.
Wenn dann innerhalb der Methode, die das Argument entgegennimmt, nicht einmal
auf spezifische Methoden / Eigenschaften des konkreten Types (List<T>) zugegriffen wird,
ist das noch ein grösser Nachteil, denn man erkauft sich eine Abhängigkeit, ohne das man sie eigentlich benötigt.
Hört sich komisch an?
Eigentlich ist es relativ leicht, wenn wir uns mal die verschiedenen Schnittstellen betrachten, worauf die Auflistungen in .NET aufbauen.
Der eigentliche Kern ist die Schnittstelle IEnumerable bzw. der typisierte Bruder IEnumerable<T>, wobei dort T den Typ der enthaltenen Elemente angibt.
IEnumerable:
IEnumerable<T>:
Das Interface IEnumerator sieht dann so aus:
(Die generische Implementation IEnumerator<T>, hat zusätzlich eine Eigenschaft vom Typ T über die Eigenschaft Current).
Anhand der Beispiele ist zu sehen, das IEnumerable / IEnumerable<T> und die dazugehörige Schnittstelle für den
Enumerator beschreibt, das Elemente durchlaufen werden können. Nicht mehr und nicht weniger.
Das Beispiel von oben, könnte wie folgt umgeschrieben werden, um die kleinste Abhängigkeit zu haben und trotzdem
alle Anforderungen funktionieren, denn es muss ja nur eine Auflistung durchlaufen werden, nicht mehr und nicht weniger.
Man beachte den geänderten Argumenttyp, der jetzt viel genereller ist.
Jetzt kann die Methode ein string[], eine List<T>, … entgegennehmen, einfach alles das die Schnittstelle IEnumerable<T> implementiert.
Wird eine Unterstützung in der Art von <Auflistung>.Count gefordert, kann die Schnittstelle ICollection<T> angegeben werden, die eine solche Eigenschaft nativ mitbringt.
Zusätzlich beschreibt das Interface (Erst ab der generischen Variante), das ein Element hinzugefügt, die Auflistung geleert, zurückgeben kann ob ein Element exisitert und Elemente entfernt werden können.
Durch LINQ to Objects können praktisch alle Operationen, wie bspw. Anzahl Elemente abfragen, sortieren, filtern, Zugriff über Index, damit und auf dem IEnumerable<T> Typen gemacht werden.
LINQ to Objects ist schnell, sehr schnell sogar. Wird jedoch die höchste Leistung benötigt und bspw. sehr häufig auf die .Count-Eigenschaft zugegriffen,
ist es besser, wenn eine native Unterstützung einer solchen Eigenschaft vorliegt.
LINQ to Objects arbeitet bei Count ungefähr so:
- Versuche die Auflistung nach ICollection<T> zu casten.
- Wenn das klappt, rufe die .Count-Eigenschaft ab und gib das Ergebnis zurück.
- Wenn es nicht klappt, durchlaufe alle Einträge in der Auflistung, zähle die Anzahl zusammen und gib das Ergebnis zurück.
Das Interface IList<T> selber implementiert ICollection<T> – kann also alles auch – jedoch gibt es zusätzlich noch die Möglichkeit nativ per Index zu arbeiten. Also Elemente indexiert abfragen, ein Element an einem bestimmten Index löschen / einfügen.
In den meisten Fällen reicht es also, wenn IEnumerable<T> als Argumenttyp bzw. Rückgabetyp angegeben wird und in den anderen Fällen jeweils das Interface ICollection<T> / IList<T>, je nachdem was benötigt wird.
Es ist zu beachten, das IList<T> nicht alles beschreibt, was List<T> implementiert, bspw. gibt es dann keine Find- / FindAll-Methode, sowie auch keine native Implementierung für das Sortieren.
Mit LINQ to Objects tritt das allerdings in den Hintergrund und so kann man sich im Code von Abhängigkeiten zu den konkreten Auflistungstypen lösen.
Wieso soll man sich überhaupt lösen?
Umso genereller die Argument- oder Rückgabetypen sind, desto flexibler ist die API und es wird nicht mehr öffentlich gemacht, als schlussendlich verwendet wird.
Zusätzlich ist die Abhängigkeit zu einem konkreten Typ weg, was bedeutet das bspw. anstelle einer List<T> einfach irgend eine andere Implementierung von IEnumerable<T> empfangen / zurückgegeben werden kann.
So kann bspw. später eine Auflistung implementiert werden, die bei einem bestimmten Ereignis wie bspw. das Entfernen eines Eintrages, einen Event auslöst, ohne den Argumenttyp zu ändern.
Folgend noch ein paar sehr interessante Beiträge zum Thema:
- The Power of Yield Return
- msdn.com - Collections
- social.msdn.com - IEnumerable
instead of IList or Collection
ASP.NET Grundlagen Teil 1: Ein Blick hinter die Kulisse
Dies ist der Beginn der Artikelserie "ASP.NET Grundlagen" mit folgenden Teilen:
- Teil 1 (Dieser Artikel)
- ASP.NET Grundlagen Teil 2: Tschüss Statuslosigkeit
ASP.NET bietet viele Features / Eigenheiten an, die auch in anderen Webtechnologien zu finden sind.
Darüber hinaus auch solche, die auf der Technologie selber oder dem Webserver (Meist IIS) aufgebaut sind.
Ablauf und Funktionsweise von ASP.NET betrachtet
Ein normaler Ablauf beim Aufruf einer Seite, dem Anklicken eines Links oder dem abschicken eines Formulars ist zwischen Client und Server bei allen Webtechnologien gleich.
Er unterscheidet sich erst ab dem Zeitpunkt wo die Verarbeitung auf dem Server anfängt. Die Ausgabe ist bei allen Technologien schlussendlich auch gleich.
- Benutzer ruft per Webbrowser eine Webseite auf, klickt einen Link an oder sendet ein Formular ab
- Beim normalen Abruf - wie das auch bei einem Link der Fall ist - wird ein GET-Request an den Server gesendet, es werden also Daten angefordert und ggf. Parameter über die Url mit übergeben (GET-Parameter)
- Bei einem Abruf über ein Formular (Egal ob durch einen Button manuell oder indirekt über Javascript abgeschickt), wird ein POST-Request zum Server gesendet und ggf. Parameter über die Url mit übergeben (GET-Parameter) und zusätzlich Formulardaten zum Server geschickt (POST-Parameter), und bei einem Datei-Upload wird die Datei binär (multipart/form-data) innerhalb des POST-Requests mitgeschickt.
Ungefähr so kann man sich die Anforderung vorstellen.
Wenn ein statische Datei angefordert wird (Bspw. ein Bild, eine Zip-Datei, ....) übernimmt im Normalfall der Webserver den Request und sendet als Response jeweils die Datei direkt zum Client - sowas nennt man dann "Download" :-).
Wenn allerdings die Dateiendung oder der angeforderte Pfad (Im Fachchargon die Resource) auf dem Webserver mit ASP.NET verknüpft ist, übernimmt ASP.NET die Verarbeitung des Requests.
Es werden die nötigen Objekte instanziiert (HttpContext, Page / HttpHandler, ...) die benötigt werden um mit ASP.NET arbeiten zu können.
All diese Objekte (Ausgenommen Applikationsobjekte) leben _nur_ vom Anfang der Verarbeitung bis zum Senden der Response, danach werden sie zerstört.
ASP.NET benutzt diese Objekte und mithilfe dem manuell geschrieben Code geschieht die Verarbeitung.
Intern läuft eine Reihenfolge von Events / Methodenaufrufen ab, was wir unter dem ASP.NET Lifecycle verstehen.
Innerhalb des selber geschrieben Codes (Page_Load, etc....) kann auf die - für den aktuellen Request - erstellten Objekte zugegriffen werden, so findet sich die GET-Parameter in "Request.QueryString[<Key>]" wieder und die POST-Parameter unter "Request.Form[<Key>].
Mithilfe des ASP.NET-Frameworks wird das abrufen und senden von Parametern auf einer höheren Ebene abstrahiert, bspw. funktioniert sowas:
Im Hintergrund läuft das automatisiert von ASP.NET ungefähr so ab:
Natürlich wird nicht genau so ein Code im Hintergrund arbeiten, aber etwas ähnliches.
Also unter der Haube von ASP.NET steckt ein wenig "Low Level" und ASP.NET abstrahiert das - vorallem durch Controls - sehr gut.
Schlussendlich wird das Resultat (Response) von ASP.NET zum Client geschickt (Page rendert rekursiv Kind-Controls / HttpHandler schickt Datei, etc...) und die ganze Geschichte fängt wieder von vorne an.
Nun, was fällt auf?
Genau: Wir haben eine komplette Statuslosigkeit.
Im nächsten Teil der Artikelserie geht es darum, was es für Möglichkeiten gibt mit der Statuslosigkeit umzugehen.
ASP.NET Grundlagen Teil 2: Tschüss Statuslosigkeit
Dies ist die Fortsetzung der Artikelserie "ASP.NET Grundlagen" mit folgenden Teilen:
- ASP.NET Grundlagen Teil 1: Ein Blick hinter die Kulisse
- Teil 2 (Dieser Artikel)
In Teil 1 gab es einen Blick hinter die Kulissen und die Erkenntnis das es der Entwickler bei Webtechnologien mit Statuslosigkeit zu tun hat.
Es gibt jedoch Möglichkeiten um die Statuslosigkeit mehr oder weniger loszuwerden bzw. mit der Statuslosigkeit umzugehen.
Auf diese Möglichkeiten möchte ich jetzt eingehen, vorallem wann / wie / was genutzt werden kann oder sollte.
SessionState
Der SessionState bietet die Möglichkeit Benutzer über eine Sitzung weg zu identifizieren.
Dies geschieht mit der Nutzung eines temporären Cookies auf dem Computer des Benutzers,
in diesem Cookie ist eine SessionId - eine Id zur Identifikation des Benutzers am Server - gespeichert.
Die Session bleibt solange bestehen, bis das Timeout nach dem letzten Kontakt mit dem Server abgelaufen ist, oder aber das Browserfenster geschlossen wird.
Anmerkung:
Wenn das Browserfenster geschlossen wird, ist die Session clientseitig verloren, serverseitig läuft sie aber noch solange bis der Timeout abgelaufen ist. Benutzt werden kann sie nicht mehr.
Anhand der SessionId können dann Daten im Arbeitsspeicher des Servers für einen Benutzer gespeichert und abgerufen werden.
Benutzt wird / sollte der SessionState primär für alles was im Benutzerkontext abläuft.
Allerdings reicht es auch hier in den meisten Fällen, bzw. ist es ratsam nur jeweils eine Identifizierung (Bentzer-Id in der Datenbank) in der Session zu speichern, da pro Benutzer gespeichert wird.
Das bedeutet - bei einer Mehrbenutzeranwendung -was ASP.NET auch ist, dass pro Benutzer jeweils Objekte im Arbeitsspeicher des Servers gehalten werden.
Diese bleiben solange im Arbeitsspeicher vorhanden, bis das Session-Timout abläuft oder aber die Daten manuell gelöscht werden.
Darum sollte darauf darauf geachtet werden, dass nur wirklich die nötigsten Daten im SessionState gehalten werden.
Nehmen wir bspw. mal eine Datenmenge von 500Kb die sich bei jedem Nutzer der Webanwendung angesammelt wird, dies bei 100 Benutzern.
500 x 100 = 50'000Kb = 50Mb. (1000Kb oder 1024Kb mal aussen vor gelassen).
Wenn während dem Timeout (Standardmässig 20 Minuten) nochmals 50 Benutzer hinzukommen, beläuft sich die Menge des benutzen Arbeitsspeicher schon auf 75Mb.
Wenn die Session-Daten im Arbeitsspeicher des Servers gehalten werden, nennt sich der Modus "InProc" (In Process), es gibt auch die Möglichkeit einen StateServer, SqlServer oder eine eigene Implementation zu verwenden um die Session-Daten auch über die Lebenszeit der Applikation zu behalten.
Cookie
Im Gegensatz zum SessionState bleiben Cookies bis zu einem gesetzten Ablaufdatum bestehen und die Daten werden auf dem Client und nicht auf dem Server gespeichert.
Das ist nütztlich um eine Funktion àla "Daten merken?" zu implementieren.
Der SessionState (temporäre Cookies) und Cookies schliessen sich also nicht nicht gegenseitig aus, sondern ergänzen sich.
So kann dieselbe Funktionalität mit dem SessionState gelöst werden und Cookies kommen dann zum Spiel, wenn die Einstellungen / Login dauerhaft, auch über eine Browsersitzung / Timout hinaus genutzt werden möchte.
Datenbank
Auch in Zusammenarbeit mit dem SessionState oder Cookies kann eine Datenbank benutzt werden, um einen Status abzuspeichern.
Der SessionState / Cookies sorgen für die Identifizierung des Benutzers und die Datenbank fungiert als Speicher.
Diese beiden Systeme (bspw. Cookie und Datenbank) assoziieren sich jeweils mit einer eindeutigen ID, sodass ein Status wiederhergestellt werden kann.
Cache
Mithilfe des Caches können Daten (Bspw. von aufwändigen Anforderungen wie die eines WebRequests oder einer langsamen Datenbankabfrage) zwischengespeichert werden, um die Anwendung zu beschleunigen.
In ASP.NET ist ausserdem das Feature "Output Cache" eingebaut, dass die aktuelle Ausgabe einer Anforderung (Bsw. einer ASP.NET Seite) zwischengespeichert werden kann.
Diese Zwischenspeicherung gilt dann (Wie auch beim normalen Cache) solange bis eine Abhängigkeit (CacheDependency) nicht mehr gültig ist.
Das kann eine Zeitdauer sein, eine Änderung einer lokalen Datei - eines Verzeichnisses oder aber etwas völlig anders (VaryByCustom oder eine eigene Abhängigkeit).
So kann bspw. für angemeldete Benutzer jeweils die Seite im Cache mit sensiblen Daten zurückgegeben werden, und bei Gästen diese ohne die sensiblen Daten, aber genauso aus dem Cache.
Ich habe den Cache hier reingenommen, da ich ihn auch für ein sehr wichtiges Mittel halte, es geht hier nicht wirklich um den Status von Client / Server sondern um die Art, Daten zwischenzuspeichern.
Application Items oder statische Variabeln
Applikationsweit _für alle Benutzer gleich_ können Daten in der Applikations-Items-Auflistung oder - läuft im gleichen Kontext - als statische Variablen gehalten werden.
Hier ist jedoch Vorsicht geboten und die Daten gehen nach einem Applikations-Neustart wieder verloren.
Auch wird hier der Arbeitsspeicher des Servers als Medium benutzt, daher sollte auch mit der Menge der Daten sparsam umgegangen werden. (Wink an Jürgen ;-)
Andere persistente Medien (Harddisk, Textdatei, ...)
Genau so wie bei der Datenbank beschrieben, können auch andere persistente Medien als Status-Speicher benutzt weren.
Seien das jetzt Textdateien, XML-Dateien, CSV-Dateien, ....
ViewState
Das ViewState-Feature das mit ASP.NET eingeführt wurde, ist sowohl alt als auch neu.
ASP.NET benutzt die Tatsache, das viele Aufrufe in ASP.NET standardmässig per POST an den Server gesendet werden,
um aktuelle Statusinformationen in einem Html-Hidden-Field zu speichern und bei der nächsten Anforderung wieder zu lesen.
Dabei lassen sich zwei Kategorien unterscheiden: Der ControlState und der ViewState.
Der Mechanismus ist der selbe, jedoch wird der ControlState nur von WebControls benutzt und kann von einem Seitenentwickler nicht deaktiviert werden.
Der ViewState hingegen wird von ASP.NET selber auf Seitenebene genutzt und kann auch von einem Entwickler auf Seite- sowie Controlebene eingesetzt werden.
Beispielanwendung:
ViewState["key"] = "value";
Mit dieser Zuweisung erfolgt serverseitig eine Speicherung als Schlüssel / Wert-Paar (Key / Value-Pair).
Alle Zuweisungen werden von ASP.NET zu einem String serialisiert und vor dem Zurücksenden des Outputs an den Client in einem versteckten Formularfeld gespeichert.
Bei einer erneuten Anforderng per POST liest ASP.NET die Werte wieder in das Objektmodell und macht sie durch den Entwickler und die Objekte die selber agieren, abruf- und zuweisbar.
Einfach gesagt: Mit Hilfe des ViewState-Mechanismus lassen sich Daten (Besser Stati) über einen PostBack am Leben erhalten.
Jedoch funktioniert das nur solange bis die nächste Anforderung nicht mehr per POST kommt, sondern bspw. per GET.
Bei einer GET-Anforderung: Also beispielsweise einen Klick auf ein Hyperlink, ein serverseitiger Response.Redirect oder einem einfachen Refresh der Seite im Browser (Ohne das mitsenden allfälliger Formulardaten) sind alle Daten im ViewState verloren und auf den Nullzustand zurückgesetzt.
Folgendes zeig dies auf:
POST -> POST -> POST -> POST (Status bleibt die ganze Zeit erhalten)
POST -> POST -> POST -> GET -> POST (Status ist ab der ersten GET-Abfrage zurückgesetzt)
Ich hoffe dass diese Artikel ein wenig Licht ins Dunkle bringen konnte und das Verständnis zu den vorhanden Möglichkeiten stärken.
Parameterübergabe in C# (by value, by reference und out)
Einleitung
Über diesen Artikel:
Ich wollte genau wissen, wie die Parameterübergabe in C# funktioniert. So bin im Netz auf die Suche gegangen und habe Tests gemacht.
Im Artikel von myCSharp wurde das Vorgehen und Verhalten gut erklärt, aber bei mir hat es dann immer noch nicht ganz "Klick" gemacht. Knifflig fand ich vor allem, wie die standardmässige Übergabe ohne irgendein Schlüsselwort funktioniert.
Zum Thema Paramterübergabe habe ich nirgends einen Artikel gefunden, der leicht zu verstehen ist und alles übersichtlich darstellt.
Nach dem Zusammensuchen von verschiedensten Informationen versuche ich nun, die gewonnene Einsicht auch für Anfänger verständlich zu erklären. Ich hoffe, dass mir dies gelungen ist und dass euch dieser Artikel gefällt.
Grundlagen zum Artikel:
- Wertetypen / Referenztypen / Stack / Heap
Scope: Anderes Wort für "Bereich" im besonderen Fall "Gültigkeitsbereich".
Referenz: Adresse der Speicherstelle, wo der Wert einer Variable gespeichert ist.
Artikel
Parameterübergabe:
Als Parameterübergabe wird der Vorgang bezeichnet, Daten an eine Methode weiterzureichen um diese in einer Methode zur Verfügung zu haben.
Entweder benutzt man diese Daten, um damit zu zu arbeiten und einen daraus folgenden Wert per "return" zurückzugeben oder auch um innerhalb der Methode ein Objekt zu benutzen, z.B. eine Node in einem TreeView einzufügen.
Parameter / Argumente:
Als Parameter wird der Wert bezeichnet, der im Methodenaufruf übergeben wird.
Die Werte, die in der Methode entgegengenommen werden, sind Argumente.
Übergabearten:
In C# gibt es drei verschiedene Möglichkeiten, um eine, bzw. mehrere Variablen zu übergeben.
Standardmässig wird vor dem Parameter kein Schlüsselwort angegeben. Dies ist eine Übergabe als Wert (by value):
Übergabe als Referenz (by reference):
Übergabe als Ergebnisparameter:
Die Schlüsselwörter "ref" und "out" müssen bei der Methodendefinition sowie auch beim Methodenaufruf deklariert werden.
Viele von euch werden vor allem von der ersten Übergabeart Gebrauch gemacht haben.
Ihr werdet euch jetzt evt. denken "Sieht doch alles praktisch gleich aus, wo liegt da der Unterschied?"
Es sieht wirklich fast gleich aus, die Unterschiede sind aber enorm und es ist gut sich über die Hintergründe zu informieren.
Verhalten bei Wertetypen:
Bei Wertetypen wird der Parameter im Normalfall, also ohne ein zusätzliches Schlüsselwort als Kopie des Wertes übergeben.
Mit dem Schlüsselwort "ref" vor dem Parameter wird die Referenz auf die Variable übergeben.
Das Argument kann anschliessend in der Methode verändert werden und die Änderung wirken sich auch auf die ursprüngliche Variable in der höheren Ebene (Scope) aus.
Wird hingegen das Schlüsselwort "out" verwendet, passiert das gleiche wie beim "ref" Schlüsselwort, mit dem Unterschied dass der übergebenen Variable beim Prozeduraufruf noch kein Wert zugewiesen werden muss, diese also noch nicht initialisiert sein muss.
Die Übergabe mit dem Schlüsselwort "out" wird verwendet, um mehrere Methodenergebnisse zurückzugeben, was anders nicht möglich bzw. nur mit Umwegen über eine Datenhaltungsklasse / -Struktur möglich wäre. Die übergebene Variable muss in diesem Fall nicht initialisiert werden.
Das Argument ist, wie bei der Übergabe per Referenz, eine Referenz auf den Wert.
Viele Funktionen der WinAPI machen z.B. von dieser Übergabeart Gebrauch.
Übergabe als Wert (by value)
Übergabe als Referenz (by reference)
Übergabe mit Ergebnisparameter (Schlüsselwort: out)
Zusammenfassung:
Übergabe als Wert (by value) "ohne Schlüsselwort":
- Kopie des Wertes wird übergeben
- Keine Auswirkungen auf den Ursprünglichen Wert unserer Variable
- Wird am häufigsten benutzt, nämlich dann, wenn die Argumente von der Methode nicht verändert werden, oder um mit einem Objekt zu arbeiten, ohne die Referenz zu überschreiben (siehe unten).
Übergabe als Referenz (by reference) "ref":
- Referenz auf Variable wird übergeben
- Ursprüngliche Variable ändert sich, wenn wir das Argument in der Methode ändern
- Die Referenz unserer Variable und unseres Arguments zeigen auf den gleichen Wert.
- Wird für Argumente gebraucht, die von der aufgerufenen Methode verändert werden sollen.
- Übergabe als Referenz ist schneller, da hier die Daten an sich nicht kopiert werden müssen, sondern nur die Referenz.
Übergabe als Ergebnisparameter "out":
- Alle genannten Punkte bei "Übergabe als Referenz" stimmen auch hier
- Übergebene Variable muss nicht initialisiert sein
- Gebrauch als Ergebnisparameter
Eine Methode kann nur einen Rückgabetyp und einen Rückgabewert haben.
Mit Hilfe der Ergebnisparameter können wir, wie im Beispiel oben gezeigt, mehrere Werte verschiedener Typen auf einen Schlag zurückgeben.
Es gibt natürlich, wie meistens :), noch andere Wege um mehrere Werte zurückzugeben. Man kann sich z.B. eine Struktur "Schlüsselwort: struct" oder eine Datenhaltungsklasse mit mehreren Feldern unterschiedlicher oder gleicher Typen definieren und diese/s dann als Rückgabetyp angeben.
Verhalten bei Referenztypen:
Bei den Referenztypen ist das Verhalten bei der Übergabe von Parameter kniffliger.
Wenn dieses nicht bekannt ist, kann es leicht zu logischen Fehlern im Programm kommen.
Das Verhalten bei der Übergabe als Referenz ist gleich wie bei den Wertetypen, es wird also die Referenz übergeben und es gilt das gleiche wie oben beschrieben. Man kann einem Referenztyp, der mithilfe von "ref" übergeben wird, auch ein vollkommen neues Objekt zuweisen.
Nach dieser Zuweisung zeigt die Referenz im Ursprungsscope dann auch auf das neue Objekt.
Bei der Benutzung vom Schlüsselwort "out" gilt dasselbe.
Bei der standardmässigen Übergabe eines Referenztypes an eine Methode müssen wir beachten, dass eine Kopie der Referenz auf unser Objekt übergeben wird.
Mit dem Objekt können wir noch genau gleich arbeiten wie auch im Ursprungsscope und den Eigenschaften Werte zuweisen.
Das normal erwartete Verhalten also.
Der Haken an der Geschichte ist aber folgender:
Wenn wir unserem Argument innerhalb der Methode ein anderes Objekt zuweisen, zeigt zwar die Kopie der Referenz auf das neue Objekt, jedoch nicht die ursprüngliche Referenz. Wir verlieren beim Verlassen der Methode die Referenz auf unser soeben zugewiesenes Objekt.
Denn diese Kopie der Referenz ist nur temporär innerhalb der Methode zugänglich.
Es wird also damit die ursprüngliche, originale Referenz vom Überschreiben geschützt.
Der Clou ist also: Wenn wir innerhalb der Methode ein neues Objekt zuweisen wollen, müssen wir die Referenz per Referenz "ref" oder out an die Methode übergeben. Alles klar?
Nicht?
Okay, ein kleines Konsolenprogramm als Beispiel wie man es nicht machen soll, in diesem Fall sollte man das Schlüsselwort "ref" benutzen:
Die korrekte Anwendung wäre in diesem Fall:
Ich habe noch eine Bilderfolge erstellt, damit man sich besser vorstellen kann, was bei einer Parameterübergabe mit Referenztypen genau passiert.
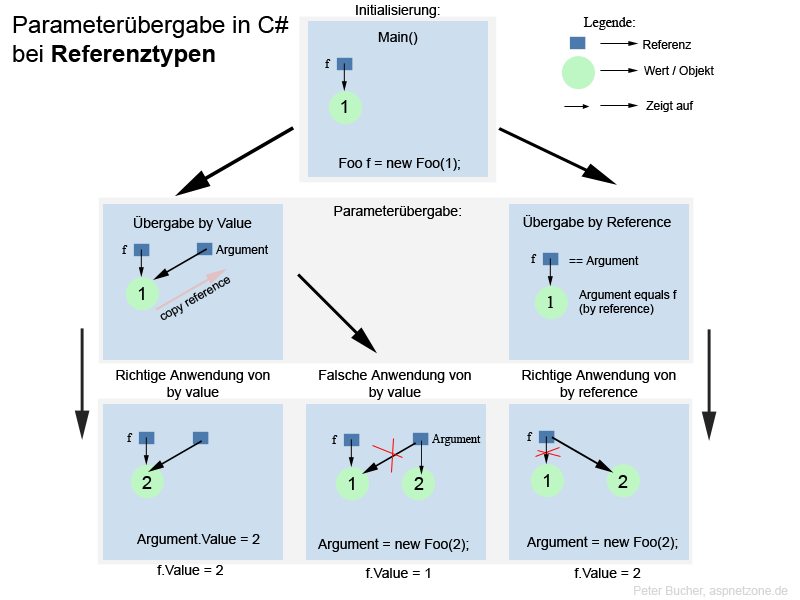
Nachtrag:
Um sich besser vorzustellen, was die ganze Geschichte bei der "täglichen Übergabe" bedeutet, habe ich noch eine kleine Tabelle erstellt.
Je nach Übergabeart der Parameter können diese in der Methode nur gelesen werden, gelesen und verändert werden oder nur verändert werden.
Besonders interessant an der unteren Darstellung ist das Verhalten bei Referenztypen bei der Übergabeart "by value".
| Übergabe von... | ...Wertetypen | ...Pointer (Referenz) auf Objekt |
|---|---|---|
| by value | Wert ist read-only | Referenz ist read-only, das Objekt jedoch read-and-write |
| by reference | Wert ist read-and-write | Referenz und Objekt sind read-and-write |
| out | Wert ist write-only | Referenz und Objekt sind write-only |
Vielen Dank für alle, die bis jetzt durchgehalten haben ;-)
Ich hoffe bei euch mit diesem Artikel evt. eine Wissenslücke ausgefüllt zu haben und freue mich über sämtliche Kommentare.
Natürlich nehme ich auch gerne konstruktive Kritik von euch an.
Weiterführende Links:
- Übergeben von Verweistypparametern (C#-Programmierhandbuch)
- Übergeben von Arrays mithilfe von "ref" und "out" (C#-Programmierhandbuch)
Quellen:
myCSharp.de: C# und Übergabemechanismen: call by value vs. call by reference (ref/out)
Microsoft Newsgroups
Internet generell
Typkonvertierung vereinfacht, oder: .To();
Im Zuge meiner Arbeit an der SessionFacade ging mir das Licht auf, dass wir es im Optimalfall mit relativ wenigen Session-Variablen zu tun haben und über eine SessionFacade auch einen einfachen typisierten Zugriff gewähren können.
Zudem finden wir in der Session im Normalfall nur geboxte Typen, die mit einem einfachen Cast zu ihrem Urprungstyp gewandelt werden können.
Da die .To-Methoden nur für das Parsen vom Typ String in einen anderen Typen gedacht ist, bringt es nichts bspw. ein geboxter int zu einem String zu wandeln um diesen nochmals zu parsen, wenn ein Cast reicht.
Zudem ist die Angabe von "object" als Zieltyp für eine Extensionmethode nicht sehr gut gewählt, da sie dann bei allen Typen erscheint. Vorallem dann natürlich nicht, wenn es relativ unsinnig ist.
Im Zuge dieser Erkenntnis habe ich den Zieltyp auf "string" geändert.
Zusätzlich gibt es auch noch die Anforderung bei einem nicht erfolgreifen Parsing auf einen anderen Typen, einen Startwert zu setzen, der vom Standardwert des Typen abweicht.
Ich habe das Beispiel unten geändert und die Erläuterung plus ein Beispiel für die zweite Überladung mit dem Standardwert hinzugefügt. Viel Spass!
Insbesondere bei der Webentwicklung mit .NET haben wir viel mit Eingaben als Strings zu tun.
Diese müssen dann in int, DateTime, double, Guid, etc... konvertiert werden.
.NET bietet dabei <Type>.Parse()- / <Type>.TryParse()- oder ConvertTo<Type>-Methoden an.
Hierbei gilt die Empfehlung <Type>.TryParse() zu verwenden um auf eine nicht mögliche Konvertierung aufgrund von Nullwerten oder ungültigen Werten zu reagieren.
Die ganze Geschichte gibt aber viel sich immer wiederholende Schreibarbeit, ein Extrembeispiel der Konvertierung eines Strings (Oder null-Literal!) aus einer GET-Parameter Abfrage zu einem int könnte mit <Type>.TryParse() so aussehen:
Für eine Konvertierung, die so häufig vorkommt ist das mir - auch aufgrund von anderen Überlegungen - viel zu viel Schreibarbeit.
Ich stelle mir sowas vor:
Zuerst meine Überlegungen:
Ob eine Konvertierung erfolgreich war, brauche ich nur den Wert zu überprüfen, einen Boolean ob die Konvertierung erfolgreich war, brauche ich nicht.
Bei int reicht mir eine Prüfung auf den Stardardwert 0, bei Guid die Prüfung auf Guid.Empty, bei DateTime entweder DateTime.MinValue.
Sind es boolsche Werte oder kann man / möchte man .MinValue von DateTime nicht benutzen, nimmt man sich Nullable Types zur Hilfe.
Mehr braucht es meines Erachtens nicht um primitive Typen sowie erweiterte Strukturen zu konvertieren und festzustellen was angekommen ist.
Ich habe mir dazu eine Methode geschrieben, die nach Wunsch entweder als Extension Method oder als statische Hilfsmethode in einer Tools-Klasse genutzt werden kann. (Das Original ist hier zu finden)
Die Implementierung:
Die Nutzung sieht dann bspw. so aus:
Diese Methode ist dafür gedacht um Strings oder geboxte Strings (Bspw. ein object das von Session[<Index>] zurückkommt aber ein String enhält in die typisierte Version zu konvertieren.
Double zu int oder eigene Objekte funktionieren nicht, dafür gibt es Casts oder man schreibt sich eigene Typekonverter dafür.
Bei normalen Typen (int, string, double, ...) wird bei der Eingabe von null oder ungültigen Strings jeweils der .NET-Standardwert (int = 0, Guid = Guid.Empty, ...) geliefert, bei der Verwendung von Nullable Types kann dann eine Prüfung gegen null benutzt werden.